近年来,人们对空气质量越来越关注。了解当地的空气污染状况对我们健康和生活质量至关重要。而想要获取准确、实时的空气质量信息,就需要从可靠且全面的数据源中收集相关指标。这就引出了爬取空气污染指数数据的必要性。
通过爬虫技术获取大量城市或地区的空气质量数据可以帮助我们比较不同地点之间的差异,并找出潜在风险高或低污染水平的区域。这样有助于人们作出更明智的决策,在选址购房、选择学校等方面能够考虑到环境因素。

及时获得精确的监测数据有利于公众提前采取措施保护自身健康。知道当前及未来天气条件下哪些特定物质(如PM2.5)达到危险水平,将使居民能够调整他们日常生活中暴露在外界环境里面时间和方式。
社会管理者也可以据此制定有效而针对性强化的环保政策。通过分析数据中的趋势、周期性和异常值,可以发现对空气质量影响较大而不易察觉的因素或事件,并根据实际情况采取相应措施,如限制工业排放、加强交通管理等。
爬取空气污染指数数据是必要且重要的。它能够为个人提供准确可靠的环境信息以保护健康,为公众选择更好的居住环境提供依据。同时也有利于社会管理者在改善空气质量方面进行科学规划和有效治理。
我们可以考虑使用Python编程语言来写爬虫代码,因为Python有丰富的第三方库和模块支持。其中,最流行和实用的是BeautifulSoup和Scrapy。BeautifulSoup是一个用于解析HTML文档的库,它可以很方便地提取页面中所需的信息。而Scrapy则是一个功能强大、灵活性高的网络抓取框架,它不仅能够处理页面解析问题,并且支持异步请求以及分布式爬取等高级功能。
除了选择合适的编程语言和库之外,在进行空气污染指数数据爬取时还需要注意一些其他技术细节。要确保自己拥有合法有效的网站访问权限,并遵守相关法律法规;在编写爬虫代码时应该设置适当的请求头信息,并加入延迟时间以防止被目标网站误认为恶意访问;在面对一些反扒措施比如验证码或登录限制时,可以尝试使用代理IP、用户账号登录或者人工干预等手段来绕过。
在选择合适的工具与技术上,请根据自己的需求和技术能力来选取适合的编程语言、库和框架;同时,在实际操作中要遵守法律规定并保持良好的网络道德行为。通过合理选择爬虫工具与技术,我们可以更加高效地获取空气污染指数数据,并应用于相关分析或决策中。
具体而言,我们可以通过以下几个步骤来进行分析。
第一步是观察目标网站的URL结构。通常情况下,获取不同城市或区域的空气污染指数数据会有相应的URL参数,例如城市代码、日期等。了解这些参数对于后续编写爬虫程序非常重要。
第二步是查看目标网站页面源代码。我们可以通过浏览器开发者工具或使用Python中的Requests库发送GET请求来获取页面源代码。在页面源代码中,我们可以找到包含所需信息(如空气质量数据)的HTML元素和CSS类名等信息。
第三步是分析目标网站上相关API接口是否可用。有时候,目标网站可能提供了API接口供开发者访问并获取所需数据。在这种情况下,直接使用API接口比解析整个HTML页面更加高效和方便。
最后一步是检查是否需要模拟登录或使用代理服务器等手段以获得权限访问特定数据。如果要访问受限制区域或需要登录才能查看特定内容,则需要进一步探索相关机制,并根据实际情况采取适当行动。
在开始爬取空气污染指数数据之前,对目标网站的结构与内容进行仔细分析是非常必要的。这将为后续编写爬虫程序提供有价值的指导,并确保数据获取顺利进行。
我们需要选择一个合适的网站或平台来获取这些数据。常见的选择包括政府部门的环境保护机构、气象局以及一些专业的空气质量监测公司。在选定目标网站后,我们需要分析该网站的页面结构和数据格式。
接下来,我们可以使用Python编写爬虫代码来获取所需的数据。通过网络请求库(如Requests)向目标网站发送HTTP请求,并获得返回结果。然后,利用解析库(如BeautifulSoup)对返回结果进行处理和提取。
针对不同网站和页面结构可能存在差异,在编写爬虫代码时需要注意遵守相关法律法规并尊重服务商设定的访问频率限制。
要获取实时空气污染指数数据,我们可以使用定时调度任务(比如cron)设置代码自动运行,并将数据存储到数据库中供后续分析和可视化展示使用。
而要获取历史空气污染指数数据,则需要根据具体需求确定时间范围,并通过循环遍历每个时间点上的页面进行爬取与提取操作。同时还应留意有些站点可能会对较旧日期、大量请求等情况加入反爬措施,我们可能需要使用适当的策略(比如伪装请求头、设置合理访问频率等)来避免被网站屏蔽或阻止。
在获取到空气污染指数数据后,我们可以进行数据清洗和处理,并结合其它相关数据(如天气、地理位置等)进行分析。这样的操作有助于我们对空气质量状况的了解,提高公众意识,以及为政府和环保组织制定相关政策和措施提供有力支持。
爬取空气污染指数数据是获取相关数据的第一步。爬虫技术可以帮助我们从公开网站或数据库中获取大量的实时或历史性空气污染指数数据。通过编写脚本程序,我们可以自动抓取所需的信息,并将其保存为适合进一步处理和分析的格式。
在进行数据处理之前,通常需要对原始的爬取到的数据进行清洗和整理工作。这涉及到去除错误或缺失值,修复错误格式等操作。在收集到足够数量样本后,还需要进行统计学分析以得出有意义且准确的结果。
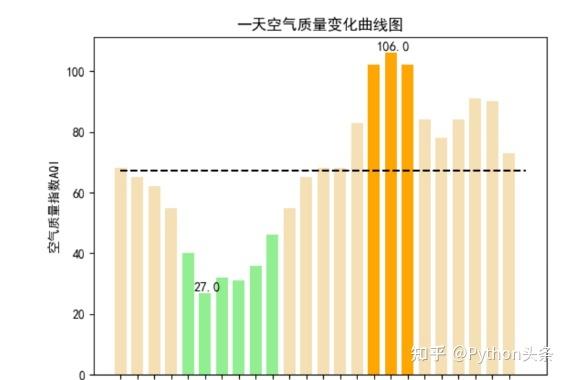
完成了数据处理后,接下来就可以使用可视化工具来展示这些已经被清洗和整理过的指标了。最常见且易于操作使用不同类型图表(如条形图、线图、饼图等)来呈现不同维度上空气污染指数变化情况会非常直观并且容易被人们理解。同时还可以利用地图等方式将不同区域上空气质量差异也能更好地展示出来。
通过爬取并处理敏感数据,并将其在可视化工具上呈现,我们能够更好地了解和分析空气污染指数的变化趋势,为相关决策提供科学依据。





评论